Understanding Pijul file graphs and change files
Posted on
Pijul represents files internally as graphs, but how does it actually work?
This article began its life when I sat down and tried in earnest to
understand how Pijul’s graph model works in practice. Personally, I
find that abstract concepts are much easier to understand when there
exists something concrete that I can mentally hook it up to. A
concrete hanger for the abstract clothing. To pursue this, I wrote
small examples, recorded them with pijul record, produced graphs
with pijul debug and tried to make sense of them. For this article I
have tried my best to make the graphs more legible without modifying
the structure produced by Pijul.
It is meant to help the reader (and myself) develop an intuition of how Pijul works under the hood, how files and directories are represented in the graph and how edits modify the graph. In the end, we will see how merge conflicts are naturally modeled in the graph. The graph model is Pijul’s tool for dealing with conflicts and it allows for recording how conflicts are resolved and those resolutions can be safely reverted.
Files and directories as graphs
A Pijul repository tracks files and folders, and changes to those. The way it does that is by modeling those objects as a graph. https://pijul.org/manual/theory.html https://jneem.github.io/pijul/ https://jneem.github.io/pseudo/
Change files
Change files consist of three parts:
- bits that are hashed
- bits that aren’t hashed
- raw byte contents (also hashed, its hash is included as a field in part 1)
Key insight: a change file is not a patch or diff in the sense that git or other diff tools might produce. A change file contains contains precise changes to an existing collection-of-files-as-a-graph (call it “repo-graph” for short).
For example: a change file never contains deleted text (like deleted lines that might appear in a unified diff). A change file may refer to content introduced by other changes and indicate parts that should be marked deleted in the repo-graph. In other words, a change file never contains deleted text, only references to text to delete.
Conversely, a given change file in isolation may only contain text/content that is being added to the existing repo-graph.
Initial graph
The initial graph is empty so there’s not really much to show, the
repository graph can essentially be thought of as containing just a
single root node.
This node is not introduced by any changes, it exist only in the
internal Pijul graph structure to anchor new graph nodes. Running
pijul debug on an empty repository produces no graph output.
Adding files
The only thing we can really do with an empty repository is to begin
adding files to it. To do that, we create a file, add some contents to
it, run pijul add <file>, then pijul record -m <message>.
Our first file graph
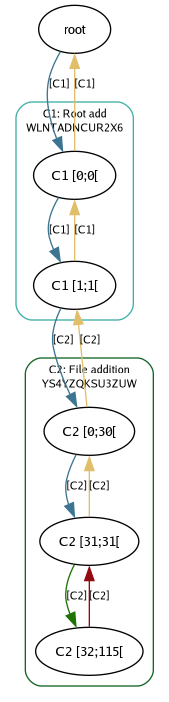
The root change (also known as AAAAAAAAAAAAA) is a synthetic node not introduced by any changes, all the other nodes are introduced by changes. The first little surprise here is that we’ve only recorded one change, but two were created. The Pijul log command confirms this:
$ pijul log
Change YS4YZQKSU3ZUXKGRK65W52EKET2UIF4V6SOZMVOEFTMXFOXJEBHQC
Author: ************ <****@*****>
Date: Wed, 18 Oct 2023 04:17:49 +0000
add main.c
Change WLNTADNCUR2X6BU4AFUIVAPTX77CORJ3T4OEXW63XPZ4ACCJ7H2AC
Author:
Date: Wed, 18 Oct 2023 04:17:49 +0000
The author-less change looks like this:
$ pijul change WLNTA
message = ''
timestamp = '2023-10-18T04:17:49.400906844Z'
authors = []
# Hunks
1. Root add
up 1.0, new 0:0
The C1 change is introduced by Pijul to “anchor” other changes. In
Pijul it’s possible to join histories from different repositories and,
as I understand it, the separate, explicit root addition is what makes
that possible. The C2 change is the actual file addition:
1. File addition: "main.c" in "" "UTF-8"
up 2.1, new 0:30
+ #include <stdio.h>
+
+ int
+ main(int argc, char *argv[])
+ {
+ printf("hello world\n");
+ }
Edits & Replacements
By far the most common operations after adding files is editing them. Pijul has two flavours of file edits: edits and replacements. The difference between the two is essentially that an edit only introduces new lines where replacements additionally remove lines.
Simple edits
The edit is rendered like this with pijul change:
1. Edit in "main.c":2 2.31 "UTF-8"
up 2.51, new 0:41, down 2.51
+
+ void saymsg(char *msg) { printf(msg); }
So all we’ve done is add two lines.
The internal graph representation in Pijul ends up looking like this.
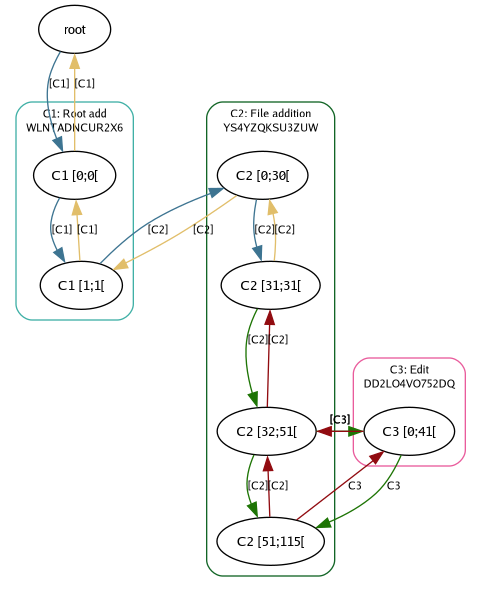
From the C2 change, Pijul has split the node C2 [32;115[ into two
nodes: C2 [32;51[ and C2 [51;115[, and C3 introduces a new node
whose contents go between them. The range notation on a node label
refers to a slice of bytes from the contents section of a given
change.
The green arrows indicate file content nodes and the order between them, and the red back arrows indicate the immediate predecessor. To render a file from this file graph, Pijul would attempt to do a total topological ordering of the content nodes, traverse them, grab the bytes from respective change files and concatenate them together to produce the final file.
In our example, the content nodes are now C2 [32;51], C2 [51;115[,
and C3 [0;41[, and Pijul orders them by the outgoing green arrows:
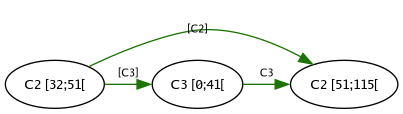
If you look closely you’ll note that the there’s one edge labeled C3
instead of [C3]. This means the edge exists only to provide a total
ordering on the nodes. The current contents of our file is literally
the concatenation of the byte sequences indicated by the three nodes.
Replacements
Next we’ll try replacing some of the existing file content with new
content. The change itself is quite simple.
Now our file graph looks like this.
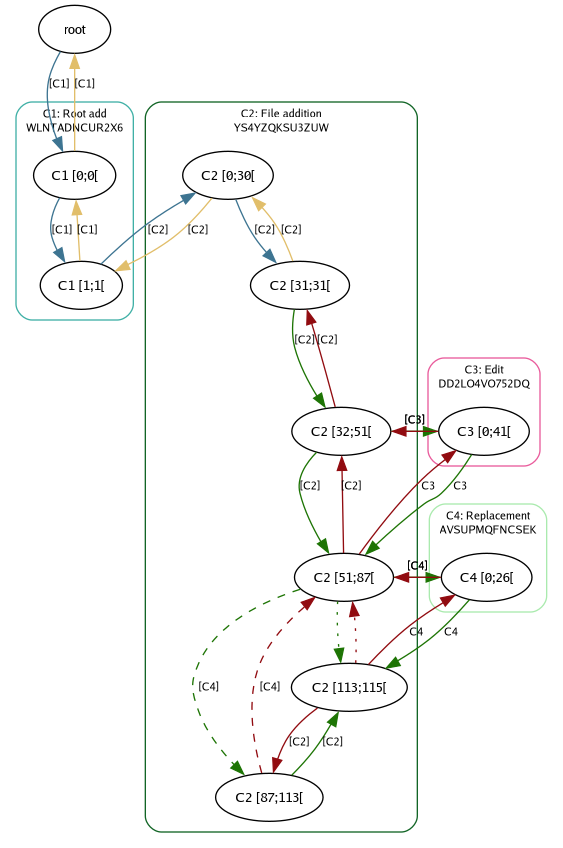
1. Replacement in "main.c":8 2.31 "UTF-8"
B:BD 2.87 -> 2.87:113/2
up 2.87, new 0:26, down 2.113
- printf("hello world\n");
+ saymsg("hello world\n");
Like C3, a new change is added with new contents, but there are some
new things to observe:
-
As with
C3, the nodes ofC2have again been split. TheC2 [51;115[node has been split into three nodes with the ranges [51;87[, [87;113[, and [113;115[. -
The middle node of range [87;113[ is the text that we have removed, and it is indicated in the graph by dashed edges introduced by
C4. -
The node with deleted content retains edges to other content nodes. Pijul considers a node “dead” if all its incoming (ie green) edges are marked deleted. It is still allowed for a dead node to have live edges to other nodes.
-
There are new dotted edges between nodes
C2 [51;87[andC2 [113;115[. These are pseudo-edges added by Pijul and are not explicitly introduced by any change. These edges exist to make it faster for Pijul to compute the live nodes without having to traverse all the dead nodes.
In general, Pijul “deletes” text by splitting a node into three: a node to hold the deleted contents, and two nodes for the remaining (alive) contents before and after. Pseudo-edges are added to make file rendering faster by allowing it to skip dead nodes.
The total number of nodes that make up the contents of our file is now five and are ordered as follows:

Adding another file
Files exist as independent subgraphs that only share a common root in the repository structure, so if we add another file to the repository it will not depend on any of the changes that introduced or modified our first file, it will only depend on the first change that introduced the root.
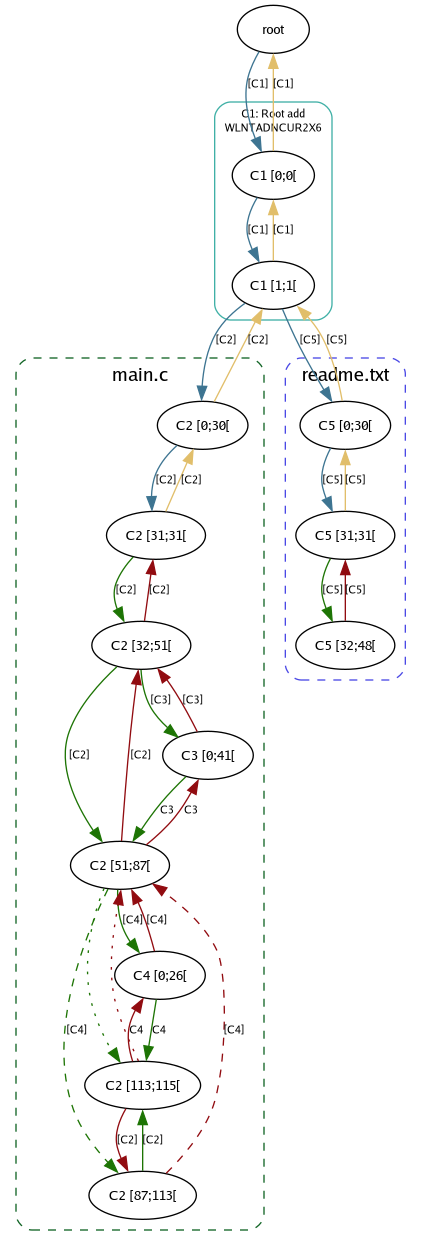 In the graph, I have removed the subgraphs that grouped nodes
from a given change and instead shown the subgraphs that represents
each of the two files now tracked by Pijul. This display is much
closer to the result from `pijul debug` piped through dot(1).
In the graph, I have removed the subgraphs that grouped nodes
from a given change and instead shown the subgraphs that represents
each of the two files now tracked by Pijul. This display is much
closer to the result from `pijul debug` piped through dot(1).
Do note that a single change can introduce more than one file at a time, and also modify many files at the same time. The presentation I have chosen here is in a sense the "cleanest" in that we have considered small incremental changes at a time.
One of the powers of the graph representation begins to come to light:
If we decided that we wanted to undo the change called C4 (the last
change on main.c) we could undo it without needing to consider the
C5 change. Our last change (adding readme.txt) does not in any way
depend on C4, so clearly we should be able to modify the part of the
file graph that represents main.c without touching the part that
represents readme.txt. If, in our last change, we had also edited
main.c, then we could have ended up depending on C4 and undoing it
would be more cumbersome, but in the current file graph that is not
the case.
Conflicts
Now that we understand better how files and directories We did not show how directories are represented in the graph, but suffice it to say it is similar to “File addition” nodes are represented internally in Pijul, we can begin to understand how conflicts are modeled.
To illustrate, we will reset the file graph that we have evolved until
now and as it can quickly become complicated and challenging to
read.
An order conflict, in which changes A and B
modify the same lines independently and, when merged, result in a
graph with live nodes that do not have an ordering between them.
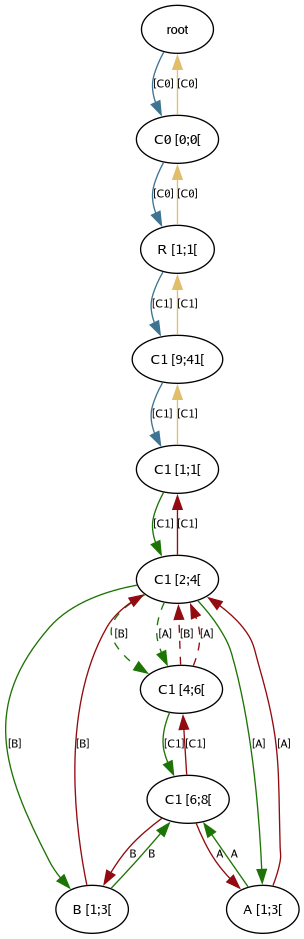 The following code creates a new repository, adds an initial file,
then creates two independent changes (using channels) that modify
the same line. The conflict is introduced by applying the change from
one channel onto the other. (In Git, this is similar to creating two
commits in different branches, then merging the branches.)
The following code creates a new repository, adds an initial file,
then creates two independent changes (using channels) that modify
the same line. The conflict is introduced by applying the change from
one channel onto the other. (In Git, this is similar to creating two
commits in different branches, then merging the branches.)
$ pijul init test --channel alice
$ cd test
$ cat <<EOF > test.txt
A
B
C
EOF
$ pijul add test.txt
$ pijul fork bob
$ pijul record --all --message "add test.txt"
$ pijul channel switch bob
$ sed -i -e 's/B/X/g' test.txt
$ pijul record --all --message "bob wuz here"
$ pijul channel switch alice
$ sed -i -e 's/B/Y/g' test.txt
$ pijul record --all --message "alice wuz here"
$ pijul apply $(pijul log --channel bob --limit 1 --hash-only)
Outputting repository ↖
There were conflicts:
- Order conflict in "file.txt" starting on line 2
- Order conflict in "file.txt" starting on line 2
$ cat test.txt
A
>>>>>>> 1 [5FA3JXMK alice wuz here]
Y
======= 1 [NXYTYEG7 bob wuz here]
X
<<<<<<< 1
C
In the graphical illustration, the change called C1 introduces our
test.txt file and then we make changes to in it different channels
where we modify the same line. Merging the changes into the same
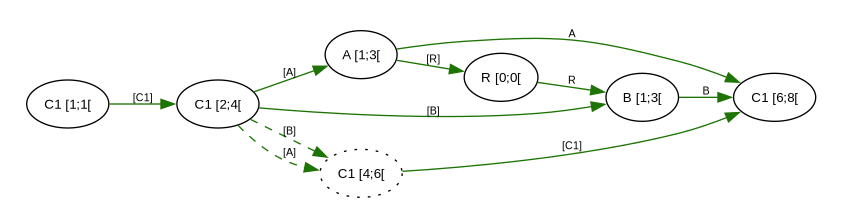
channel results in an order conflict. The nodes A [1;3[ and B [1;3[ do not have any forward arrows from one to the other to impose
a total ordering. The live nodes in the file graph are now only
partially ordered.
In general, a conflict in Pijul is concretely the situation where multiple changes make modifications to the underlying file graph that results in a graph where there is no total ordering among all the live nodes.
If we focus on just the nodes that make up the contents of our file, the graph looks like this:
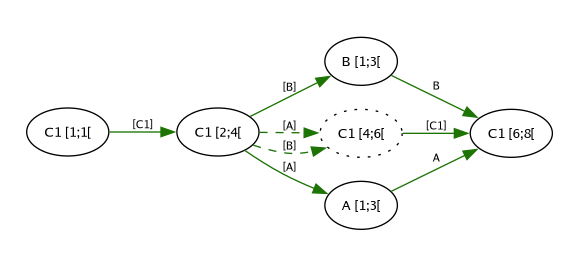
Both changes delete the text represented by C1 [4;6[ and replace
them with their own text, but there is no relation between the new
nodes. When Pijul outputs the file, the conflict (more specifically,
an order conflict) is identified. Pijul then produces the file with
conflict markers and prints a message informing about the conflict and
its location.
In the Pijul repo-graph model, there are different kinds of conflicts and they are enumerated.
-
An order conflict is when there is not one unique ordering among all the text nodes that make up a file’s contents
-
A zombie conflict is when one change deletes text that is modified by another change. Zombie conflicts also occur with files, where one change edits a file and another deletes it
-
There are also name conflicts stemming from renaming files or introducing files in different changes with the same name
-
There are even cyclic conficts which, at the time of writing, I am not confident enough to attempt to explain
All these kinds of conflicts are modeled in the repo-graph and allows Pijul to “remember” conflicts.
To resolve a conflict, we need to add another change. Conflict resolution is a specific type of change, where a total ordering is added to the repo-graph. The simplest form of conflict resolution does nothing more than add the necessary forward edges between nodes to reinstate a total ordering on all the live nodes.
We will apply this simplest resolution and remove the conflict markers in our file to indicate we want those lines in that order. Recording this change in Pijul produces a new change type:
# Dependencies
[2] 5FA3JXMKJAW4CZ5SDKQNE4X7ZGGS4SU27IDQGC4WEJ3DPBBCPXUAC # alice wuz here
[3] NXYTYEG7LFI2COMCN3JZXR7GXKHHH5Y3IUNWRZZJ6KSKCZMMIL3QC # bob
wuz here
[4]+NDZBWWPUTO3QMOZ4UMZZGETAZQPGPJZJDY74FR7VICYUKO3RF3LAC # add test.txt
# Hunks
1. Solving an order conflict in "test.txt":3 4.1 "UTF-8"
up 2.3, new 0:0, down 3.1
The change file itself has no contents! The one hunk it contains only
contains information about the graph. Specifically, a node R [0;0[
is added to the graph with forward edges going from A [1;3[ to
B [1;3[. Now our live nodes have a total ordering among them again.
The astute reader will have noticed that at no point were nodes or edges removed from the graph. This is a feature of Pijul, it is an append-only system. There does not appear to be a safe way to remove nodes or edges without potentially causing problems later on.
If you made it this far, thank you for reading! I know it was a long read.